Módulo de lógica difusa (Fuzzy Logic Toolkit)
En una aplicación típica de tratamiento (procesamiento y análisis) de imágenes, es generalmente deseado separar y clasificar objetos contenidos en una imagen en función del valor de ciertos atributos. Este proceso es llamado clasificación y reposa sobre el análisis de atributos de forma, tamaño, color, posición, textura, etc.
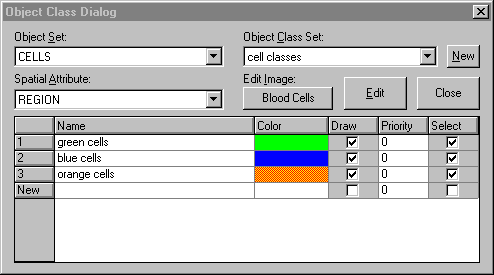
Para soportar este proceso, Aphelion™ propone un módulo de lógica difusa que pone a disposición de los usuarios métodos de lógica binaria y difusa, que permiten crear reglas definiendo de que manera la información extraída de las imágenes debe ser interpretada. Este modulo permite a los usuarios de transmitir el conocimiento a priori que ellos tienen sobre el contenido de la imagen y las diferentes categorías de objetos, facilitando de esta manera el análisis automático de los objetos.
Múltiples reglas pueden ser combinadas con el fin de definir una clasificación que sea lo mas cercana posible a la decisión humana. Dado que estas reglas son en general mas que simples decisiones SI o NO, el módulo propone por lo tanto reglas que se pueden adaptar al contexto, es decir, reglas capaces de franquear el ruido, una potencial ambigüedad en los datos, o aun errores cometidos en la fase de aprendizaje. Si es necesario, las reglas pueden hacerse binarias afín de aproximarse a una decisión de tipo SI o NO. La principal diferencia con los otros sistemas de clasificación es que la lógica utilizada es independiente del código, lo cual permite fácilmente visualizarla, interpretarla y modificarla.
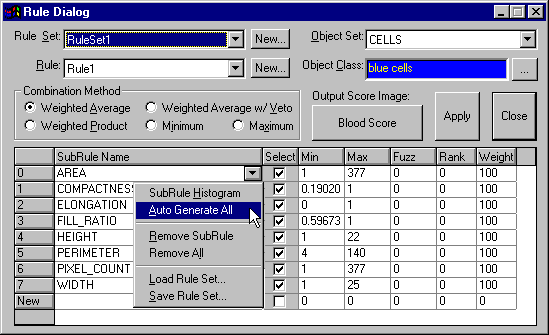
El módulo de clasificación de Aphelion, utilizado en combinación con las funciones de segmentación y conversión de objetos disponibles en el software, permite a los usuarios de crear procedimientos de análisis que reproducen decisiones que serian tomadas por expertos. Los usuarios sin experiencia en programación pueden así ingresar rápidamente al modulo conocimiento sobre la forma como los datos deben ser interpretados, instruyendo de este modo al computador en como duplicar el proceso de toma de decisiones.
Otra ventaja de esta técnica es que la fase de aprendizaje puede ser realizada a partir de un conjunto pequeño de datos, dado que las estadísticas no están involucradas. La interpretación de los datos reposa sobre la plausibilidad y no sobre la probabilidad, y la clasificación reposa sobre las informaciones presentes en los datos y no en la frecuencia de ocurrencia de estos. Inversamente, los métodos de clasificación basados en análisis estadísticos o redes neuronales requieren cientos de muestras de entrenamiento como mínimo. Además, tales sistemas son sensibles al orden y frecuencia de ocurrencia de las clases representadas en los datos de aprendizaje, lo cual no sucede en los sistemas basados en lógica difusa.