Module de logique floue pour Aphelion™ Developer (Fuzzy Logic Toolkit)
Dans une application typique de traitement et analyse d’images, il est souvent nécessaire de séparer et classer des objets appartenant à une image en fonction de la valeur de certains attributs. Ce processus est appelé classification et repose sur l’analyse de la valeur des attributs de forme, taille, couleur, position, texture, etc.
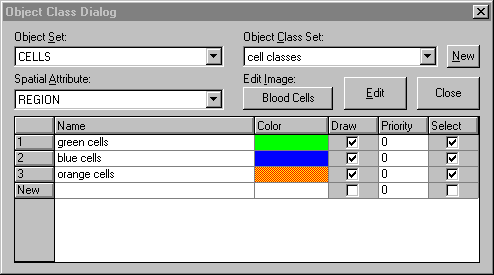
En standard, Aphelion propose un module de logique floue qui met à la disposition des utilisateurs des méthodes de logique binaire et floue afin de créer des règles définissant de quelle aminère l’information extraite des images doit être interprètée. Ce module permet ainsi aux utilisateurs de transcrire la connaissance à priori qu’ils ont du contenu de l’image et des différentes catégories d’objets, facilitant ainsi l’analyse automatique de ces objets.
Des règles multiples peuvent être combinées afin de définir une classification qui se rapproche le plus possible de la décision humaine. Parce que les règles généralement sont plus que des décisions de type Oui ou Non, le module propose ainsi des règles pouvant s’adapter au contexte, c’est à dire capables de s’affranchir du bruit, d’une potentielle ambiguité dans les données, ou même des erreurs commises lors de la phase d’apprentissage. Si besoin est, les règles peuvent être rendues binaires afin de s’approcher le plus possible d’une décision de type Vrai-Faux. La différence majeure avec d’autres système de classification est que la logique utilisée est indépendante du code, ce qui permet de la visualiser aisément, de l’interpréter et de la modifier.
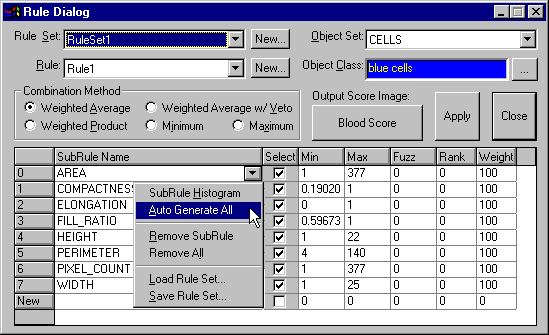
Le module de classification d’Aphelion utilisé en combinaison avec les fonctions de segmentation et la conversion en objets disponibles dans le logiciel permet aux utilisateurs d’effectuer des analyses reproduisant des décisions qui seraient prises par des experts. Les utilisateurs novices peuvent ainsi apporter au module des connaissances sur la manière dont les données devraient être interprètées, Aphelion se chargeant par la suite de dupliquer le processus de décision.
Un autre avantage de cette approche est que la phase d’apprentissage peut être effectuée sur un petit lot de données, puisque les statistiques ne sont pas mises en jeu. L’interprétation des données repose sur la plausibilité et non sur la probabilité, et la classification repose sur les informations présentes dans les données et non sur la fréquence de cette occurence. Inversement, les méthodes de classification reposant sur l’analyse statistique ou les réseaux de neurones requièrent des centaines d’échantillons au minimum. En outre, ces dernières méthodes sont sensibles à l’ordre et la fréquence de l’occurence des classes représentées dans l’ensemble constituant l’apprentissage, ce qui n’arrive pas dans les systèmes basés sur la logique floue.